看这本书时做的笔记. 总结一下:
1. 有众多可以参考的地方, 例如 Cron 的设计, 监控的改进, 新工具的推广方法
2. 对手头的系统和工具要非常了解, 这样就可以玩出很多招数
## 1. 介绍
* DevOps 在 Google 的实践
传统开发/运维分离的解决方案在规模扩大后沟通成本上升(“随时发布” vs. “不再改动”) -> 新型运维团队 SRE(50%-60%标准开发, 其他为85%-99%能力的开发, 为了开发系统代替手工操作) -> 最多 50% 时间用于运维工作, 余下开发系统来自动化
* SRE 方法论
* 运维工作最多占用 50% 时间
* 遇到故障事后写总结
* 因为信息系统的特点, 不是也不该追求 100% 可靠, 给出现实的可靠性. 在实现这个可靠性的前提下, SRE 可以做各种创新
* 监控, 通过预案/手册缩短平均恢复时间
* 70% 的事故源于部署变更 -> 渐进发布, 精确检测, 回滚机制
## 2. 生产环境
* 集群资源分配: Borg(分布式集群操作系统), 下一代 Kubernetes(2014)
* Large-scale cluster management at Google with Borg
* Borg, Omega, and Kubernetes
* 负责运行用户提交的任务. 每个任务由多个实例组成, Borg 会为每一个实例安排一台物理服务器, 执行具体的程序启动它
* 负责任务的监控, 如果异常, 终止并重启
* 命名: BNS: /bns/<cluster>/<user>/<task>/<instance>
* 任务需要在配置中声明其所需的具体资源(cpu/mem), 超过则立即 kill
* 存储
* 分布式存储, 小文件和大文件进不同的集群.
* 单个集群一年内会损失上千块硬盘, 数据中心有专门的团队来处理
* 网络
* 这些概念比较陌生, OpenFlow 的软件定义网络, 带宽控制器优化带宽.
* 从地理位置, 用户服务和远程调用三层进行负载均衡
* 监控报警
* 定时抓取指标, 超出触发报警
* **新旧版本的对比: 新版本是否让软件服务器更快了?**
* 检查资源用量随时间的变化, 制定资源计划.
* 服务
* 所有服务使用 RPC 通信, 开源实现为 gRPC
* 格式为 Protocol Buffer(与 Apache Thrift 相比) (大小比 xml 小 3-10 倍, 序列化/反序列化快 100 倍) (和 json 比?)
* 服务和存储根据流量分散到各大洲的机房
* 开发
* Code review
## 3. 拥抱风险
* 目标
* 没有 100% 可靠的服务, 达到一定程度的可靠性之后, 应把精力转向他处.
* **”当设立了一个可用性目标为99.99%时, 我们即使要超过这个目标, 也不会超过太多, 否则会浪费为系统增加新功能, 清理技术债务或者降低运营成本的机会.”**
* 可靠性目标成为错误预算: 提供明确和客观的指标决定服务在一个季度中接受多少不可靠性(用于 SRE 部门和产品部门的沟通). 只要错误预算耗尽, 新版本的发布就会暂停(?但是错误率由 SRE 部门提供, 而发布由产品决定?) -> 认为风险由产品开发决定, 一个变通是, 当错误预算即将用尽时, 降低发布的频率. 即使是网络中断或者数据中心故障影响了错误率, 发布频率也会降低, 因为”每个人”都有义务保障服务的正常运行.
* 可用性指标: 请求成功率. **用我们记录的请求成功率与用户期望的服务水平做对比.**
* 成本
* 可用性: 99.9% 到 99.99%; 收入: 1000000刀 -> 改进后的价值: 1000000 * 0.09% = 900 刀
* 需求
* 面向消费者需要低延迟(队列空为好), 离线计算需要吞吐量(队列满为好). 需要分别响应不同的需求. -> 两个集群, 低延迟/高吞吐量
## 4. 服务质量
* 质量度量
* 请求延迟 (Req time)
* 错误率 (Web errors)
* 吞吐量 (Web QPS)
* Google 云计算的可用性指标: 99.95% -> 60*24*365*0.0005 = 262.8 min/year -> 我们的可用性?
* 特色
* 4/5个指标, 多/少都不好.
* 监控, y 轴指数分布
* 数据收集每10秒一次, 每一分钟汇总一次. 目标像这样: **99% 的 get RPC 调用在 < 100ms 的时间内完成.**, 每天可以出一个这样的报表.
* 总结
* 指标越少越好, 少到不能更少
* 性能指标保持简单
* 从松散的目标开始, 逐渐收紧. 不要一开始就追求完美
* 对内指标要求可以比对外高一些, 留有余地
## 5. 琐事
* 与规模线性增长的手动事务
* 占用 Google SRE 大约 33% 的时间
## 6. 分布式系统的监控
* 方式
* 白盒: 系统内部数据
* 黑盒: 外部响应
* Dashboard: 可视化, 提供选择/过滤功能
* 警报
* 如何监控
* 对照组: 上周, 上一个版本
* 减少报警量(防止”狼来了”)
* 简单快速的逻辑. 不要自动学习阈值(这点和我想的不一样) **避免在监控系统中维护复杂的依赖关系**
* 方法论
* 故障, 警报, 定位和调试都必须保持简单!
* 4个关键指标: 延迟, 流量, 错误率, 饱和度(IO 带宽占用比, 磁盘占用比)
* 长尾
* 重要的是分布而不是平均 -> 直方图 Y 轴指数展示
* 复杂性管理
* 避免监控系统变得过于复杂
## 7. 自动化系统的演进
* shell 脚本 -> 改进后的 Python 单元测试框架(Prodtest, 改进的 Python 单元测试框架, 可用来对实际服务进行单元测试), 用于验证集群中的服务(比如 DNS 是否存在/成功)
* 在 Prodtest 出来之后, 又为每个 test 创建了对应的修复工具.
* 集群上线系统的测试-自动化修复套件的问题:
1. 需要维护!
2. 2. 分布式自动化依赖于 SSH, 需要 root 权限执行. => 需要将 SRE 完成任务所需权限降到最低. => 使用有 ACL 的本地 admin 进程取代 sshd, admin 记录 rpc 请求者, 参数和结果.
* Borg: 成功的核心是”把集群管理变成了一个可以发送 API 的中央协调主体”. 所以 shell 脚本 => Python 集群测试框架(自动化系统) => Borg(自治系统, 将集群管理抽象为单机环境) => 自治系统强调自我检查和自我修复.
* 自动化的问题: 自动化多了, 人就忘了手动该怎么做. 甚至系统将不再有手动操作的接口.
## 8. 发布
* 构建过程的封闭性, 不受构建机器上第三方类库和其他软件工具影响. 编译过程自包含, 不依赖编译环境之外的其他服务.
* 构建工具与被构建的项目放在同一个仓库. (而我们的做法是分离的. 应用开发者按照平台提供的规范走, 不管构建的事. 各有好处. 这样平台在构建过程上可发挥的空间更大)
* 单独的发布分支(避免引入之后主分支上的改动). 发布系统将创建新的发布分支, 编译, 跑单元测试. 每一步都有日志记录.
* 部署. “提供一系列可扩展的 Python 类, 支持任意部署流程”. 同时会对流程进行监控.
* 经验: 在规模不大时就考虑发布工程, 尽早采用最佳实践(尽早建立平台团队?)
## 9. 简单化
* 问题: 代码膨胀. 态度: “每一行新代码都是负担”, less is more.
* 方法: 最小 API(方法更少, 参数更少), 模块化(定义良好的边界)
## 10. 基于时序数据的报警
SRE 的职责层级关系(低 -> 高):
监控
应急处理
事后总结和问题根源分析
测试
容量规划
研发(50%+ 的精力)
监控首当其冲.
* 方法论: 单机问题报警没有意义(太频繁).
* 模型: 探针(脚本返回值 + 图形展示) 转到时序信息监控. 收集回来的数据同时进行展示和报警, 报警规则由数学表达式表示.
* 接口: /varz HTTP 列出所有的监控变量值, 由 Borgmon 定时抓取. (看来在应用所在每个机器上都有)
* 报警: 每条报警规则都有一个持续时间, 只有当警报持续时间超过一定范围之后才触发报警. (有借鉴意义, 尤其是对可自动恢复的问题); 同时多条连续的报警信息可以合并.
## 11. On-call
* 运维工作时间上限是50%工作时间, 其中不超过 25% 的 on-call.
* 分钟级的 ack. 比如 99.99% 可用的系统, 每个季度有 13 分钟的不可用时间, 那么 on-call 必须在 13 分钟之内解决问题(不过这里的”问题”看来是影响全局服务的大问题)
* “面临挑战时, 人有两种处理模式: 1. 依赖直觉, 快速, 自动化行动 2. 理性, 专注, 有意识认知活动. 为了确保 on-call 采用第二种方式, 必须减少其压力. 医学上讲, 压力状态下释放的荷尔蒙, 如 xx 和 yy, 可能造成恐惧, 进而影响正常认知..” 哈哈哈, 这个态度我喜欢, 必须把不理性的情况考虑到, 避免运维压力过大.
## 12. 故障排查
* 大型系统中, 遇到问题首要做的是尽可能恢复服务, 而不是查找问题根源.
* 将故障排查测试的项目明确写出来, 同时公布测试结果.
## 13. 紧急响应
* 演习: “SRE 故意破坏系统, 模拟事故, 然后针对失败模式进行预防以提高可靠性” => 鼓励主动测试
* Panic room: 专用的灾难安全屋, 有生产环境的专线连接.
## 14. 紧急事故管理
* 出了事故, on-call, 开发, 管理者, 这些关注到的人都在用自己的方法查找并尝试解决问题.
* 都在查找原因, 没有人有精力和时间思考如何通过其他手段缓解当前的问题.
* 没有时间清晰和有效地与其他人进行沟通, 没有人知道他们的同事在干什么.
* 解决: 职责分离. 有事故总控(需要明确声明现在开始全权负责, 任务分配), 事务处理团队, 发言人和规划负责人(提供支持).
## 15. 事后总结
* 总结: 1. 记录事故 2. 理清根源 3. 采取有效措施使得重现概率最低
* 对事不对人
* 总结报告需要评审
* 举办演习, 再现某篇事故总结事故, 一批工程师扮演文档中提到的角色
* 激励做正确事情的人(“良好的事后总结和事故处理可以赢得从 CEO 到工程师的一致好评”)
## 16. 跟踪故障
* 报警的聚合(一个问题引发了一连串报警)和加标签.
## 17. 测试可靠性
没看懂. 摘一下最后一句话: ”写出优质的测试需要付出的成本是很大的”. 现在写写单元测试没问题, 依赖众多的分布式软件的集成测试还不明白怎么弄.
## 18. SRE 部门中的软件工程实践
* 分析了一个案例, 对扩容需求做了一个应用, 包括需求的定义语法规则和对应的问题求解器. 一开始是简单的启发式逻辑, 后来使用线性规划使其更加聪明. 总结是体现了”发布与迭代”的思路, 不是一开始就期待完美的设计, 而是不断继续前进.
* 讨论了新工具的推广. 公告邮件和简单的演示是不够的, 需要持续和完整的推广方案, 用户的拥护和管理层的帮助. 设计的时候, 要时刻从用户角度提高可用性.
* 不要陷入对”完美的最终产物”的想象中. 一个”最小可行产品”是必要的, 在此基础上进行递进式的, 稳定的小型发布.
* 后期引入有统计学和数学优化背景的人进行优化.
## 19. 前端负载均衡
一致性哈希.
负载均衡器的包转发:
* NAT, 需要在内存中追踪每一个连接, 否定
* 修改数据链路层信息(MAC 地址), 需要后端服务器在一个局域网, 否定
* 包封装, 将请求使用路由封装协议封装到另一个 IP 包中, 使用后端服务器地址作为目标地址, ok.
## 20. 数据中心负载均衡
* 随机轮询:
1. 多个进程共享某个后端时, 其客户端请求速率可能是不同的. 如果一台后端上恰好跑的都是请求速率块的进程, 那么其负载就高.
2. 物理服务器不同
* 最闲轮询:
问题是, 一些任务在处理过程中是跑满了 cpu, 一些则是在阻塞. 但最闲轮询(基于任务数量)会认为负载是一样的.
* 加权轮询:
将最闲轮询的”任务数”替换为综合请求速率, cpu 占用率等计算出的值, 实践中效果更好.
## 21. 过载
## 22. 连锁故障
连锁故障由故障进入正反馈引发. 典型的例子是: 一个集群故障 => fallback 到另一个集群 => 另一个集群某服务受影响变慢 => RPC 超时, 大量重试 => 这个集群也不堪重负挂掉.
* 应对方法: 压力测试极限, 提供降级结果, 在可能导致问题时主动拒绝请求.
* 去除同层调用, 保持调用栈持久向下.
* 压力测试, 直到出现故障
## 23. 分布式共识
* 问题定义: 异步式分布式共识在消息传递可能无线延迟的环境下的实现
* 不能通过简单心跳实现
* 不稳定的条件下, 没有任何一种异步式分布式共识算法可以保证一定达成共识
* Paxos: 有严格顺序的提案被大多数接收者同意, 已被 zk, consul, etcd 等封装. 最出版本的 Paxos 有性能问题
* 复合式 Paxos: Paxos 两阶段: prepare/promise, 允许跳过第一阶段. 但是有锁住的危险. 更好的算法参考 Raft.
## 24. Cron
这里的 cron 是允许错过的, crond 不记录执行信息, 只会记录 schedule.
**定义问题**
cron 分为两类: 可重复的(垃圾回收)和不可重复的(邮件发送).
上面是跑多了的情况, 也有跑少了的情况: 有的 cron 允许错过一次(垃圾回收), 有的不允许(每月结算)
这两种情况导致 cron 的错误建模很复杂. **本文偏向于错过运行, 而不是运行两次**, 因为错过可以手动启动一次, 跑了两次是覆水难收的.
总结: 可以少跑, 不能重复跑
**大规模部署**
最小周期也是每分钟.
也是使用的容器, 主要考虑的功能是进程隔离: 一个进程不该影响到另外的进程.
容错. 调度器确保在数据中心的另一个地方有备份.
总结: 最小粒度每分钟, 调度器有多重实例, 通过 paxos 确保一致性
**Cron at Google**
对 cron 的状态, 有两种选择:
* 存到分布式存储(GFS)
* 存到 cron service
选择的第二种. (GFS 适合大文件存储)
使用 Paxos 算法确保 cron service 的一致性. paxos: 通过多重不可靠的副本达成可靠的一致性.
最重要的信息是**哪个 cron 已经跑过了.**
cron 调度器有多个备份待命, master 负责启动 cron job.
master 的工作流程:
sleep 直到时间到, 向 data center scheduler 发出启动指令,
同时发 paxos, => 其他 replica 知道任务已经启动
启动完毕后再发 paxos. => 其他 replica 知道任务启动完毕
=> cron job 跑完自己结束(解决了并行执行的问题), master 只管启动, 但是一定要成功启动.
确保只有一个调度器与 data center scheduler 交互, 一旦失去 master 地位, 就停止交互.
这里”发 paxos 告知开始启动”和”发 paxos 告知启动完成”中间有个时间段, 这个时间段就是启动时间. **这点很好, 现在 marathon 缺少这个, 你可以告诉他要做什么任务, 但他不会告诉你什么时候完成**
总结: cron 启动状态通过 paxos 与备份同步, 确保只有 master 能与 data center scheduler 交互, 只管启动不管结束
**启动失败**
再次重申, cron job 启动时候有两个同步点: 开始启动和启动完成. 如果 master 在这二者的中间失败, 我们就难以知道启动是否真正完成.
解决方法是使启动操作(master => 启动操作(data center scheduler 执行) => 完成)都是可重入的. 启动操作实际上是一系列的 rpc 操作(我想是类似 redarrow?)
不可避免的是失败. 如果在 rpc 发出 - 启动状态发送到 paxos 之间 master 挂掉, 那么新的 master 可能不知道这个 cron 已经启动, 还是可能导致重复启动. 这种小概率的事件就看你要不要继续付出代价来防了.
**存储状态**
paxos 基本是一个状态变化的连续日志. 这带来两个问题: 1. 日志分段 2. 日志存储
日志分段用打 snapshot 的方式解决: 我猜这里是把日志分成两部分: 之前的日志打成 snapshot, 之后的作为增量. snapshot 保险存放. 那么即使丢失, 丢掉的也是增量, 在一个可控的范围内.
对日志存储, 有两个选择: 分布式存储和系统本地卷. 选择是两种都做: 在所有 master 和备份的本地存(一共3个), 同时写到分布式存储.
**大规模带来的问题**
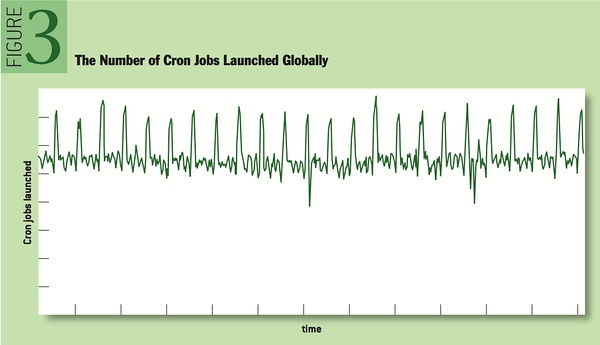
大规模: 为上千台节点的 data center 提供 cron 服务. 如果这些 cron 都集中到同一时间段就不好了. 举例: 当想要一个每天跑一次的 cron 时, 很多人都会写:
`0 0 * * *`, 拿这时候的 cron 密度就比较高.
提供了一种新格式, `? ? * * *` 表示由 cron master 选 cron 时间, cron master 利用这种写法将其均匀分布:
-
《SRE》读后感
xindoo 2016-10-02
3赞
原文来自:http://blog.csdn.net/xindoo/article/details/52723114
《SRE》这本书英文版已面世半年后,中文版终于面世。从4月、5月的时候,我就一直在尝试看英文版,由于自己英文水平有限,阅读进度和深度实在有限,看到中文版,对很多章节的内容才算是有了较深入的理解,一句话评价此书,这是一本运维转型的指导性书。
看过原版,再对照中文版,从内容上,并不比原版少什么,所以各位读者不必担心内容相对原版是否缺失,如果各位英语不好、但又想了解Google的SRE,放心大胆的买中文版吧,因为译者也是Google的前SRE,翻译的不能说原汁原味,但也八九不离十。
我自己本身也在国内某大厂做运维,我们也面临着传统运维向devops的转型,接下来我就结合自己实际工作的经历,谈谈我对这本说的理解。
这本书基本上可以分成几个大部分。
* SRE的诞生
* Google内部软硬件环境
* SRE和Dev的协作
* SRE自己是如何做事的
SRE是为了解决op和dev相互之间的矛盾和割裂的问题,用一些工程和规范来让op和dev之间有个平衡,并且最优化系统的发展。书中举出大量dev和sre系统的方法和规范,比如错误预算、部分运维工作交还dev、SRE协助dev团队健康发展等……
从我自己的经验来看,其实作为一个op,一天到晚有一堆乱七八糟的事,曾经因为这些事,搞的我情绪都不太好。不同于国内一些公司,google考虑到了这些,制定了一系列的标准来平衡SRE工作上的问题,比如最多50%运维工作、完善的轮值机制、完善的SRE培训体系……,前两天还看过google的《重新定义公司》,从他们内部各种福利政策来看,google是一个非常人性化的公司。
运维工作中,有些是管理层需要做的事,但也有些内容能让你自己提升自己运维的效率。这么多年,SRE总结出了一套完善的方法论,比如和Dev团队的协作沟通,SRE在风险管理、on-call、故障排查、问题处理、故障后总结……,google都总结出了想当好的经验。
书中也介绍了google的一些软硬件环境,比如数据中心、网络、borg、Chubby(zookeeper)、监控系统、负载均衡、cron等。书中介绍了一些这类软硬件设计的思路,可以给那些想自己设计软硬件系统的公司一些方向。
> We want our systems that are automatic, not just automated.
>
上面这句话是英文版原文,如何理解这句话?我们想让要系统是自治的,而不仅仅是自动的。这是一个设计系统先进的理念,想想我们往常是怎么设计系统的,是不是专注于解决一个问题,流程在这里卡了,需要人为干预,甚至是再做一个新的系统来解决某些问题。
举个例子,一个应用有数十台服务器,服务器会宕机,然后需要把服务器下线,再扩容一台。然后就会有一个监控系统发现问题,再弄个服务器下线的系统,自动化扩容的系统,然后都需要手工提单。这个时候,有人嫌提单麻烦,又写了个自动调其他三个系统解决问题的系统。就因为服务不是自治的,而我们一味强调自动化,导致系统越来越复杂,越来越难以自动化。其实我举的这个例子,google的borg已经很好的解决了,我认为borg基本上就是一个自治的系统。
总结一把,我觉得这本书并不是直接告诉你应该怎么做,因为不同的公司在不同的阶段关注的重点是不一样的,做的事也不可能和google相同,盲从某些方法论可能会得到x'fan相反的结果,所以我的建议是把这本书当成一种方向性的指导。
